
By now, most of us are familiar with Large Language Models (LLMs) like ChatGPT. But to understand the significance of these models, let’s step back in time to the 1900s. Imagine you have a pressing question in science and need an answer. How would you find it?
You’d likely start by asking friends or people nearby. They might provide some direction, but your curiosity wouldn’t end there. To dive deeper, you’d head to the library, where indexes and catalogs would guide you to the most relevant books for your topic. These indexes, much like a map, help you quickly locate information instead of aimlessly searching through shelves. After hours of reading, highlighting, and taking notes, you’d have gathered enough information to begin piecing together an answer.
Fast forward to the present. Thanks to decades of technological advances and the rise of the internet, we can automate this process now through LLMs. These models, trained on vast amounts of human-created text, help connect the dots across topics. However, like your friends from the 1900s, LLMs can only answer questions based on the general information they’ve been trained on—they don’t have access to your organization’s unique knowledge. That’s where RAG comes into play. RAG enhances LLMs by providing access to specific company knowledge, enabling them to deliver more accurate and contextually relevant answers.
What is RAG?
RAG stands for Retrieval-Augmented Generation. It is more of an idea, a workflow of sorts that helps us answer domain specific questions that the users ask.
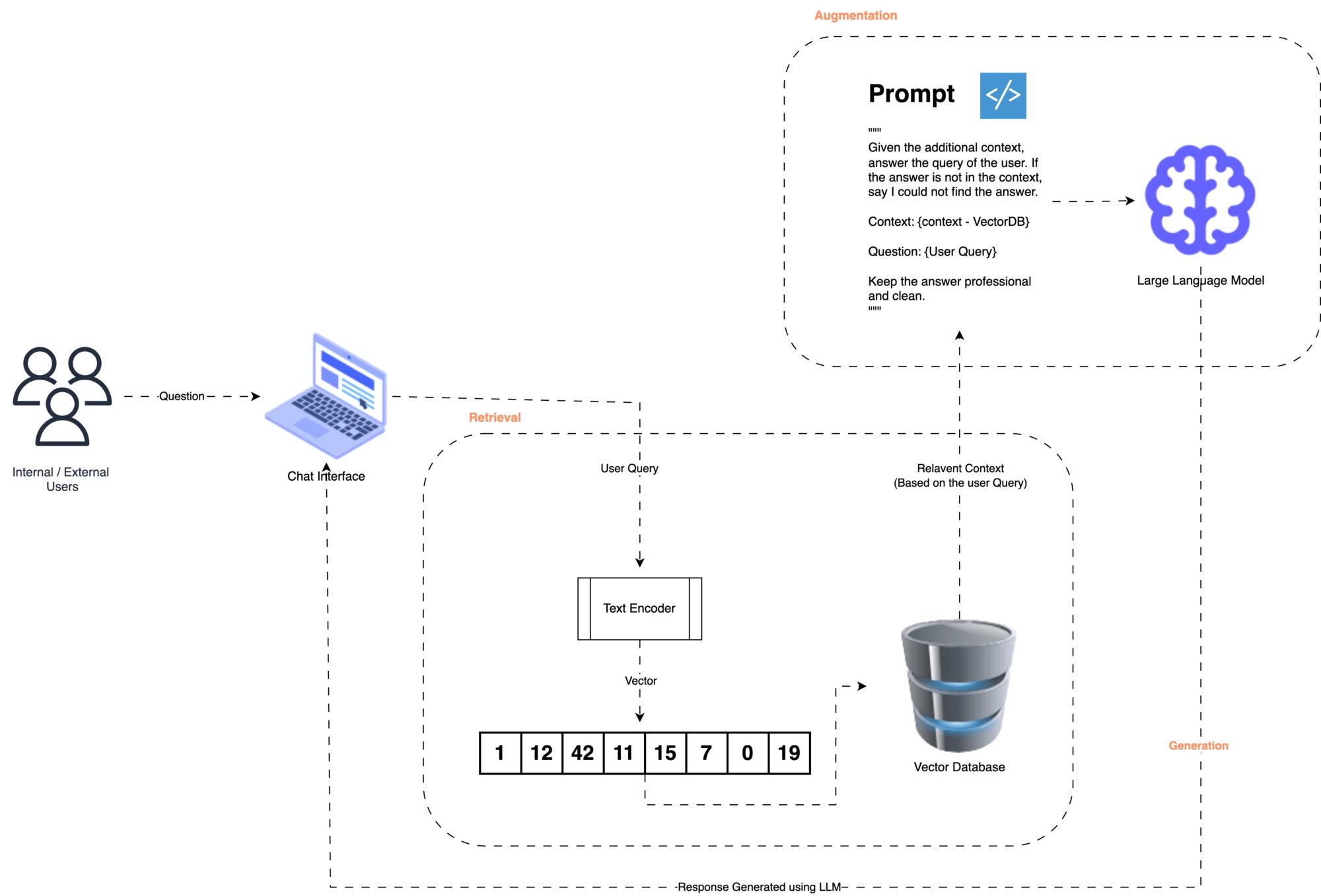
Retrieval: Think of this as the library trip. Given a question, RAG retrieves the most relevant documents or information from a database, similar to how library indexes help you find the right books. This step provides LLMs with specific resources needed to address your query.
Augmentation: This step is like taking notes and highlighting key passages in the library books. By augmenting the LLM’s general knowledge with this additional context, the model gains a deeper understanding of the topic specific to your needs.
Generation: Finally, the generation stage resembles connecting the dots based on both what your friends shared and the information you uncovered in the library. Here, the model synthesizes the information to answer your question accurately and thoroughly.
But …RAG pipelines are complicated
While RAG may seem like a straightforward concept, implementing it involves a lot of intricate steps. Let’s return to our library analogy. One of the biggest assumptions we make is that the library has correctly indexed the books, enabling us to locate relevant information quickly. In the same way, RAG systems rely on accurate indexing of company knowledge in a Vector Database. If this isn’t done correctly, the RAG pipeline may fail to provide the relevant context required to answer specific questions.
In this blog post, we’ll introduce five essential workflows in a RAG pipeline:
- Loading Data: This step is like gathering books from the library. It involves collecting data from sources such as SharePoint, OneDrive, Google Drive, and other repositories. Connectors are needed to load data and track any updates, such as adding, modifying, or deleting files.
- Indexing Data: Just as libraries create indexes to make content searchable, we need to organize relevant text from each document into chunks. These chunks are converted into vectors (numerical representations of text) that the machine can process and understand.
- Storing Data: This is akin to the library’s cataloging system. All indexed data is stored in a specialized Vector Database, which excels at quickly storing and searching through vectors.
- Querying Data: This step mirrors searching for a book in a library database. The RAG system uses a “similarity score” to find documents that closely match the vector generated by the user’s query, ensuring only the most relevant information is retrieved.
- Evaluation of Responses: Given that RAG systems generate responses automatically, ensuring their accuracy is crucial. Evaluation provides objective metrics to gauge the reliability of model-generated answers.
Each of these steps introduces unique challenges and considerations. While we won’t delve into each one in this post, stay tuned for our upcoming blogs in this GenAI blog series, where we’ll explore the intricacies of RAG pipelines in detail.
Why RAG really matters?
Now that we’ve covered what RAG is, let’s discuss why it’s so impactful. What makes RAG the go-to solution in today’s AI landscape, and why is there so much buzz around it?
- Enhanced Relevance: Unlike traditional LLMs, RAG allows models to draw from domain-specific knowledge, resulting in responses that are more relevant and contextually accurate for specialized fields.
- Scalability: With the right setup, RAG can be scaled across various domains and departments, tailoring responses to each area’s unique needs.
- Efficiency: By narrowing down vast amounts of information to just the essentials, RAG reduces the need for extensive manual searches, making it highly efficient for both internal and customer-facing use cases.
- Adaptability: RAG systems can continuously learn and adapt as new data is added, allowing organizations to keep their models updated with minimal effort.
In a world where information is constantly evolving, RAG enables companies to leverage their unique knowledge base effectively. It’s not just about answering questions but about answering them with precision, relevance, and speed—qualities essential for modern business operations.
